
はじめに
無料で使えるPythonのデータ解析ライブラリ 「pandas」で、CSVを出力(書き込み)をする方法を紹介します。「難しい内容は抜きにして、PandasでCSVファイルを出力する方法が知りたい」という方は是非ご覧ください。
行番号無効化の方法(Indexオプション)も併せて解説します。
環境
この記事は以下の環境で作成しています。
| 環境 | バージョンなど |
| Python | 3.9.6 |
| pandas | 4.7.2 |
| OS | Wiindows10 |
「Windows10 + Python + pandas + venv」の環境で作成しています。(AnacondaやJupiterNotebookは使用していません)
「環境やインストール方法が知りたい」という方は、こちらの記事をご覧ください。
コードの概要
コードの概要は以下の通りです。「CSVファイルの読み取り」「データ追加」「CSVファイルの書き込み」を行います。
- CSVファイルの読み取り
- データの追加
- CSVファイルの書き込み
実行結果
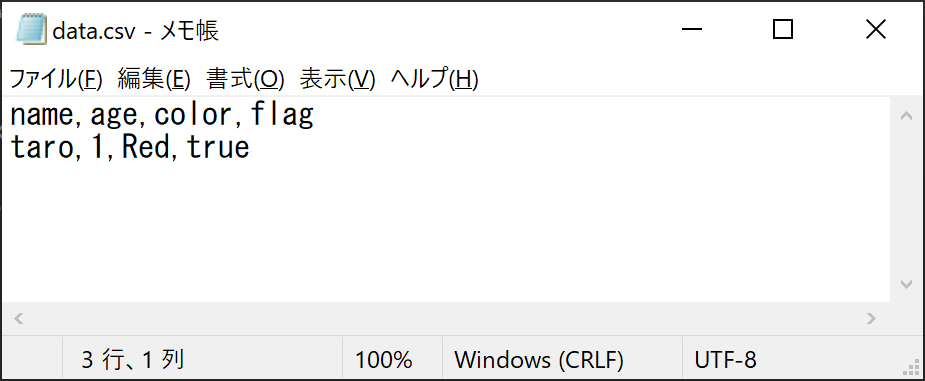
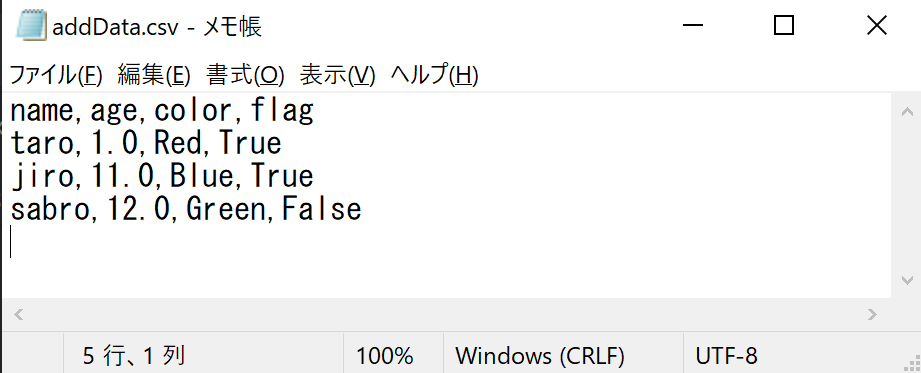
後述する「CSVファイルを出力するコード」の実行結果は以下の通りです。既存のCSVファイル「data.csv」にデータを追加したものを「addData.csv」として出力しています。
全体コード
「CSVファイルを出力するコード」 は以下の通りです。詳細は後述の「コードのポイント」をご覧ください。
import pandas as pd
import os
# CSVファイルを読み込みます
# 自動的にDataFrameの形式になります
df = pd.read_csv("data.csv")
# CSVデータを表示します
print(df)
# データを追加します
df.at = ["jiro" ,11,"Blue" ,True ]
df.at
= ["jiro" ,11,"Blue" ,True ]
df.at = ["sabro",12,"Green",False ]
# 追加後のデータを再表示します
print(df)
# フォルダを作成します
os.makedirs("SaveFolder", exist_ok=True)
# CSVファイルを出力します
df.to_csv("SaveFolder\\addData.csv", index=False )
# index オプションなし
# df.to_csv("SaveFolder\\addData.csv")
= ["sabro",12,"Green",False ]
# 追加後のデータを再表示します
print(df)
# フォルダを作成します
os.makedirs("SaveFolder", exist_ok=True)
# CSVファイルを出力します
df.to_csv("SaveFolder\\addData.csv", index=False )
# index オプションなし
# df.to_csv("SaveFolder\\addData.csv")コードのポイント
read_csv関数で便利にCSVを読み込む
read_csv関数を使って、CSVファイルを読み込みます。
pandasのCSVファイル出力する場合、出力するデータは「DataFrame」か「Series」形式である必要があります。
今回使うread_csv関数は、対象データを自動的に「DataFrame」の形式で読み込むので、後でそのままCSVファイルへ書き込むことができます。
# CSVファイルを読み込みます
# 自動的にDataFrameの形式になります
df = pd.read_csv("data.csv")※ DataFrameの詳細はこちらの記事をご覧ください。
atプロパティで行を追加する
DataFrame型のプロパティ 「at 」を使って行を追加します。使用していない行番号にデータを代入すると、新規の行が追加できます。
# データを追加します
df.at = ["jiro" ,11,"Blue" ,True ]
df.at = ["sabro",12,"Green",False ] ※ atプロパティの詳細は、こちらの記事をご覧ください。
to_csv関数でCSVファイルを出力する
to_csv関数に保存したいフォルダ名(パス)を指定して、CSVファイルを出力します。
以下のコードは、実行するPythonファイルと同じ場所にある「SaveFolder」フォルダを指定しています。
# フォルダを作成します
os.makedirs("SaveFolder", exist_ok=True)
# CSVファイルを出力します
df.to_csv("SaveFolder\\addData.csv", index=False )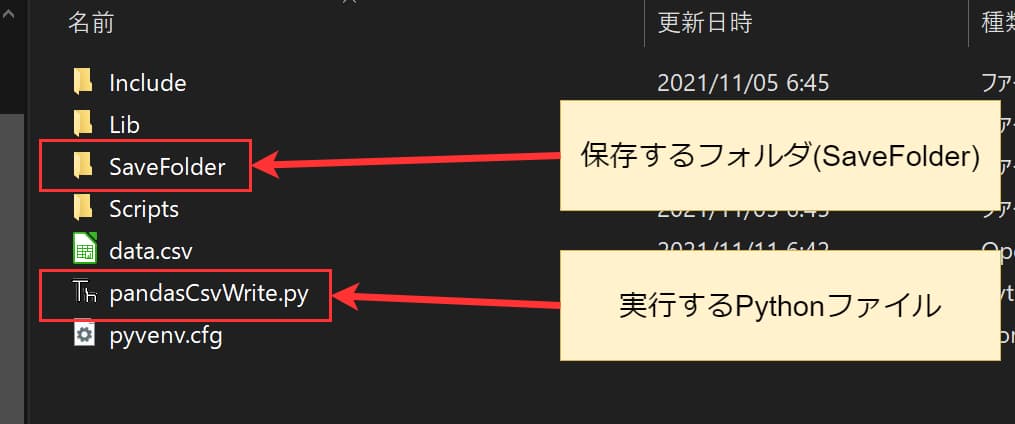
to_csv関数ではフォルダは自動作成されません。
フォルダを新規作成したい場合は、os.makedirs() などで予めフォルダを作成してください。フォルダがない場合にto_csv関数を実行すると、FileNotFoundError が発生します。
行番号の無効化
pandasでは、先頭に行番号(Index)がついていないCSVファイルを読み込むと、データの先頭に自動的に行番号が追加されます。
この行番号は出力時も残るため、ファイル出力時に元ファイルとフォーマットが変わってしまう、という問題が発生します。
上記問題には、to_csv関数にindex=Falseを指定することで対処可能です。Falseを指定することで、行番号のファイル出力を無効化できます。行番号を有効/無効にした例を以下に示します。
行番号が出力される例
index=Falseを指定しないと、行番号が出力されます。
# index オプションなし
# df.to_csv("SaveFolder\\addData.csv")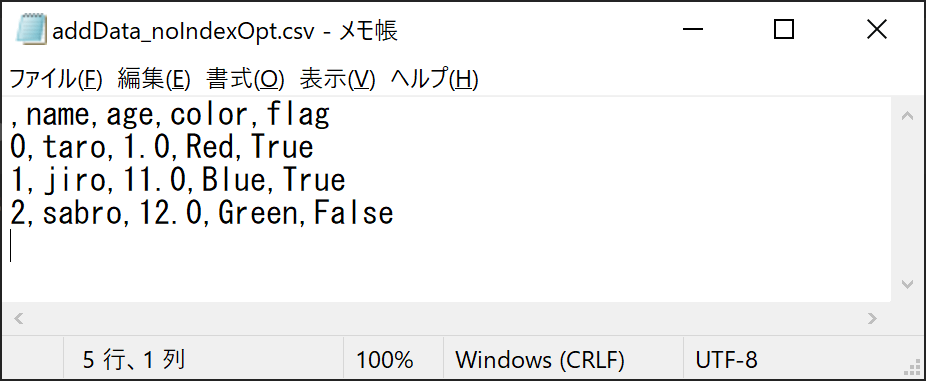
行番号が出力されない例
index=Falseを指定すると、行番号は出力されません。
# CSVファイルを出力します
df.to_csv("SaveFolder\\addData.csv", index=False )まとめ
無料で使えるPythonのデータ解析ライブラリ 「pandas」で「CSVの出力(書き込み)をする方法」と「行番号の無効化」について解説しました。参考になればうれしいです。
pandas CSV その他の記事
CSVの読み込み時のShift-JIS対策も解説しています。興味のある方はご覧ください。
質問・要望 大歓迎です
「こんな解説記事作って」「こんなことがしたいけど、〇〇で困ってる」など、コメント欄で教えてください。 質問・要望に、中の人ができる限り対応します。
使えたよ・設定できたよの一言コメントも大歓迎。気軽に足跡を残してみてください。記事を紹介したい方はブログ、SNSにバシバシ貼ってもらってOKです。









